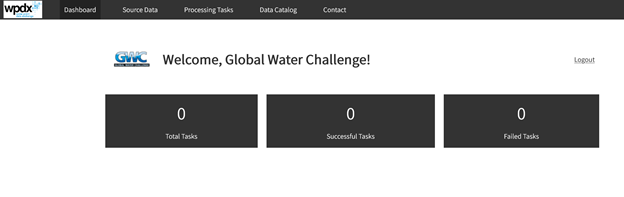
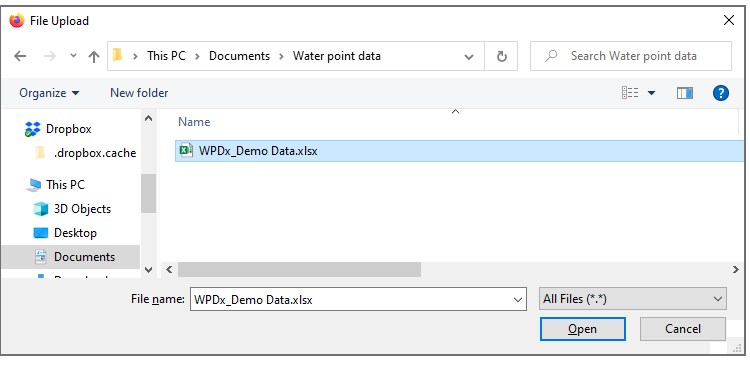
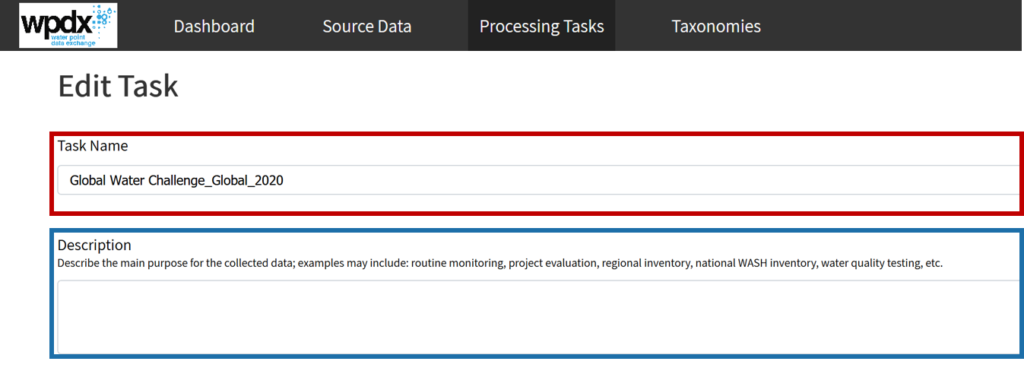
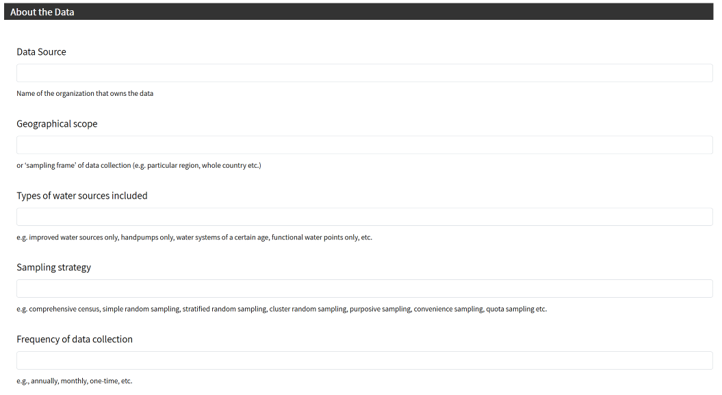
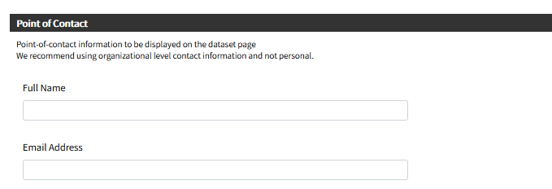
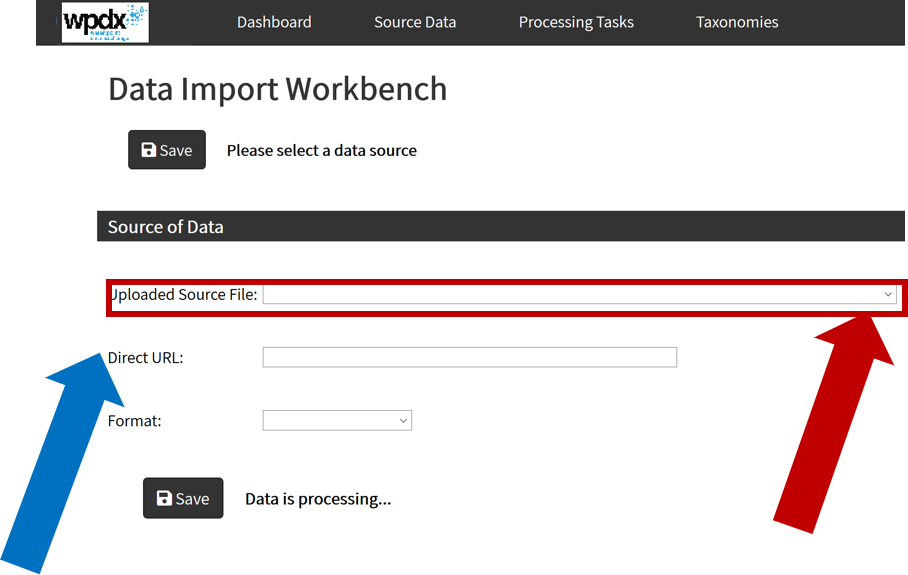
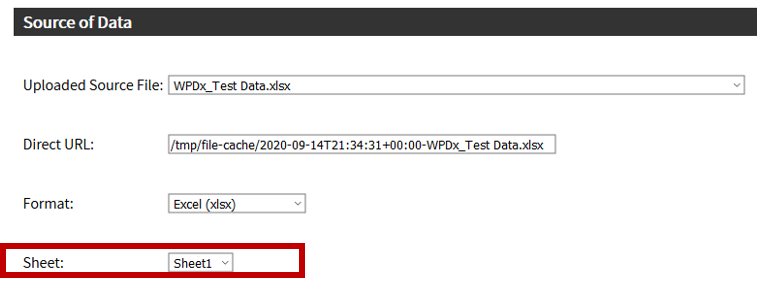
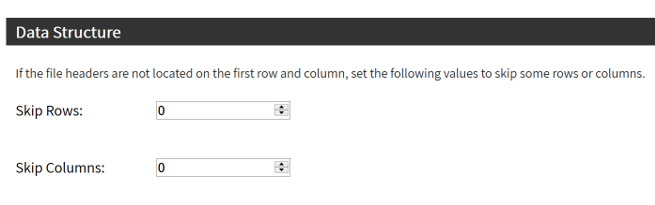
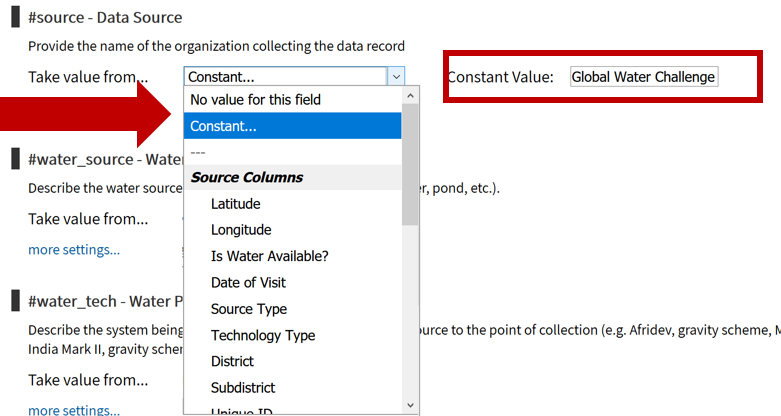
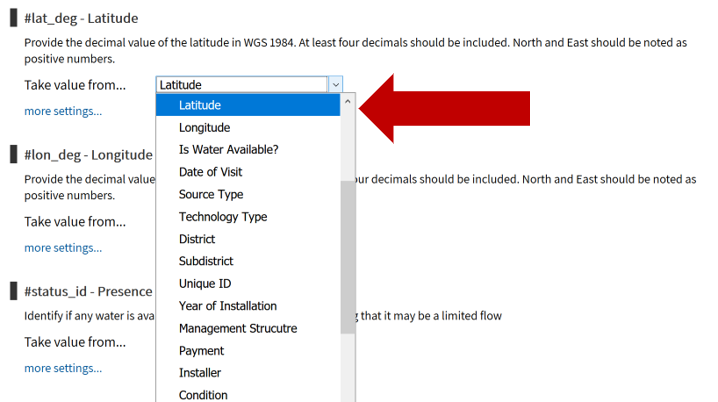
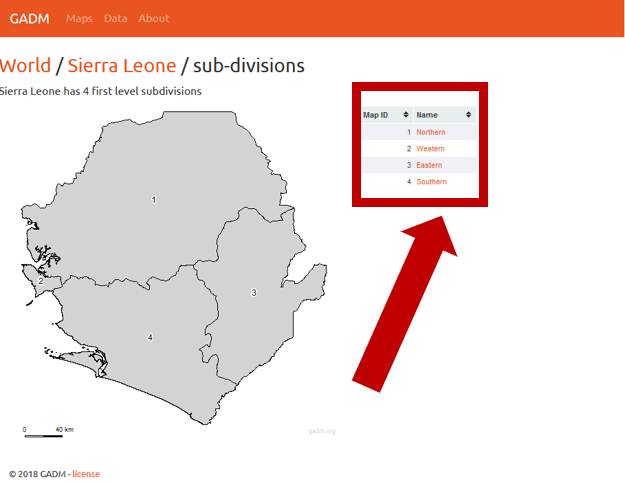
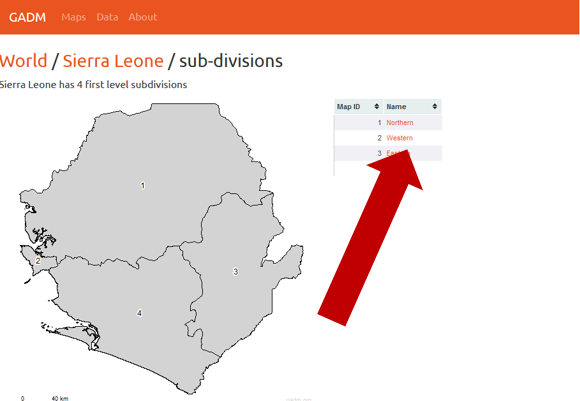
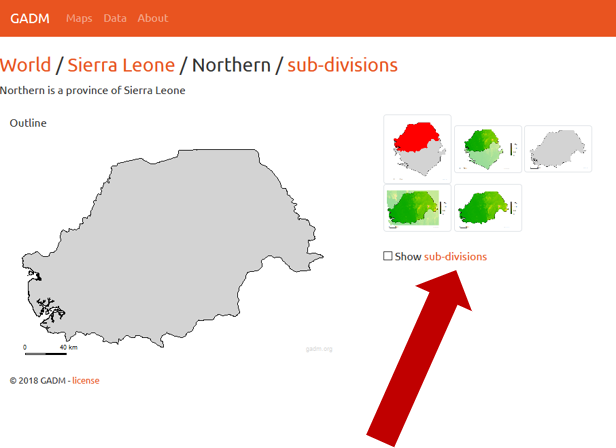
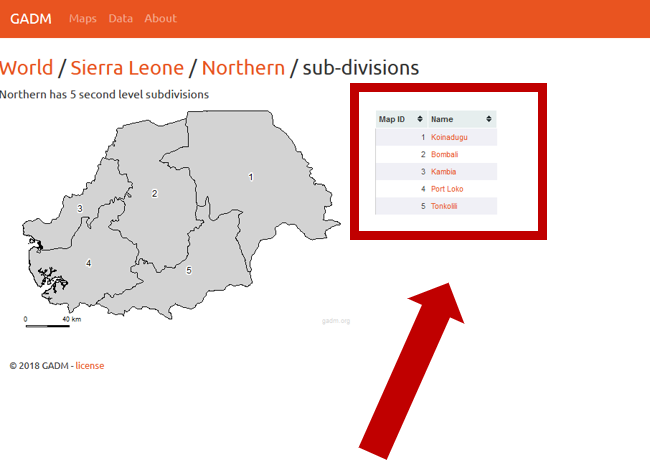
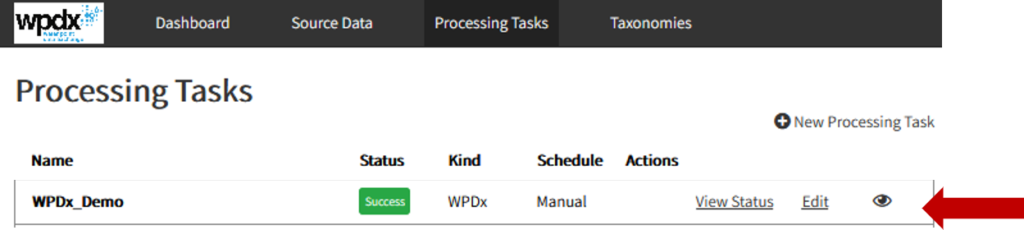
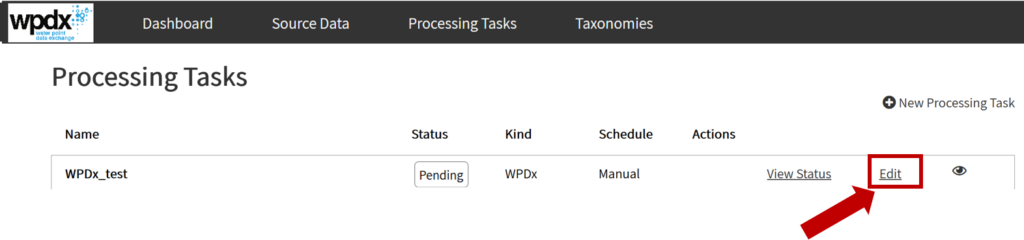
Sharing data with WPDx has never been easier. In fall 2020, WPDx completed a major overhaul of our ingestion engine to streamline the process for data sharing. This blog will take you step-by-step through the upload process. In most cases, this will take less than 30 minutes to complete! If you have questions, please reach out to info@washhealthdata.org.
Before you start, please review our Data Submission Policy to ensure that you have the correct permissions to share the data.
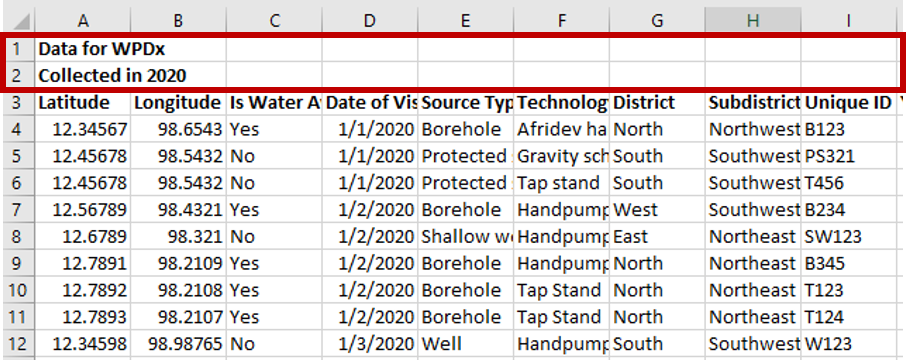
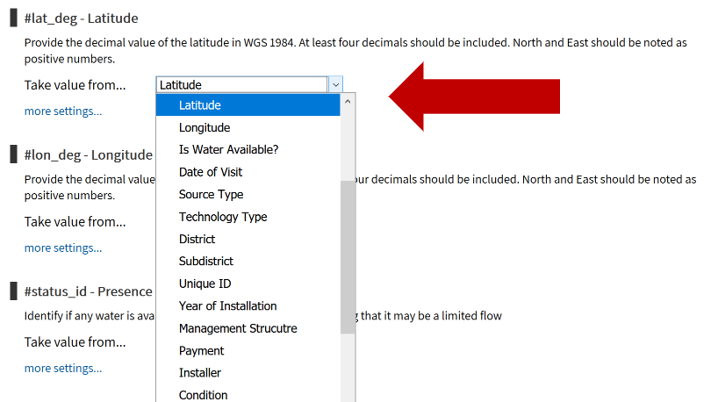
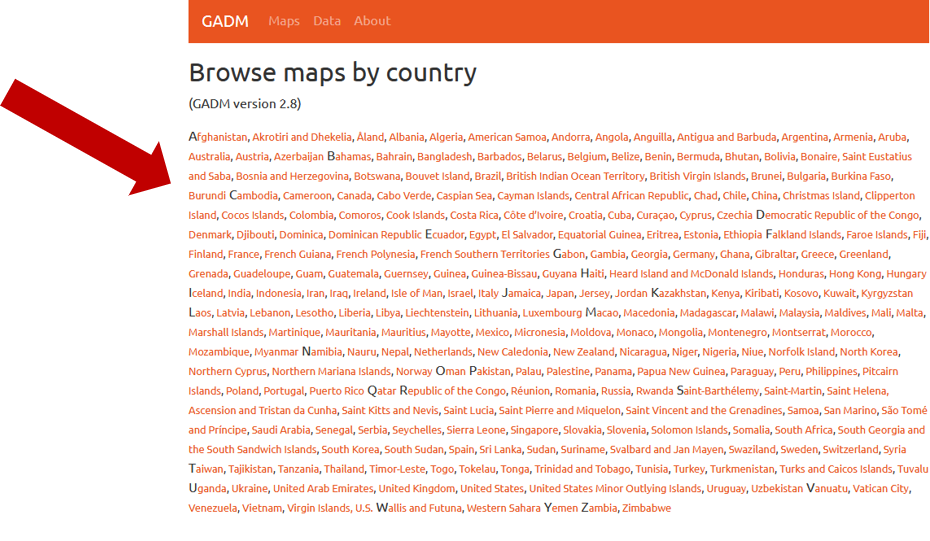
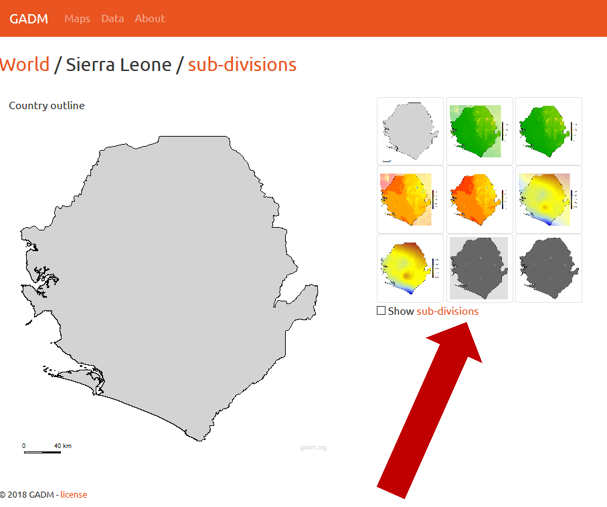
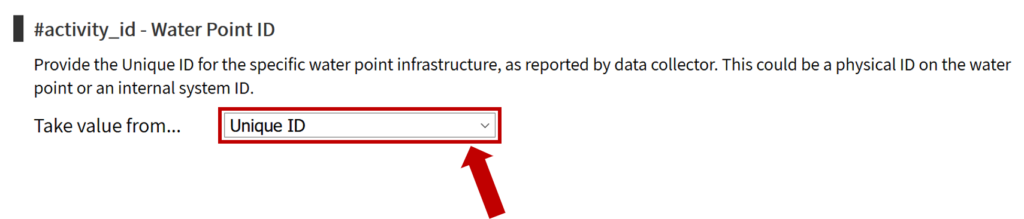
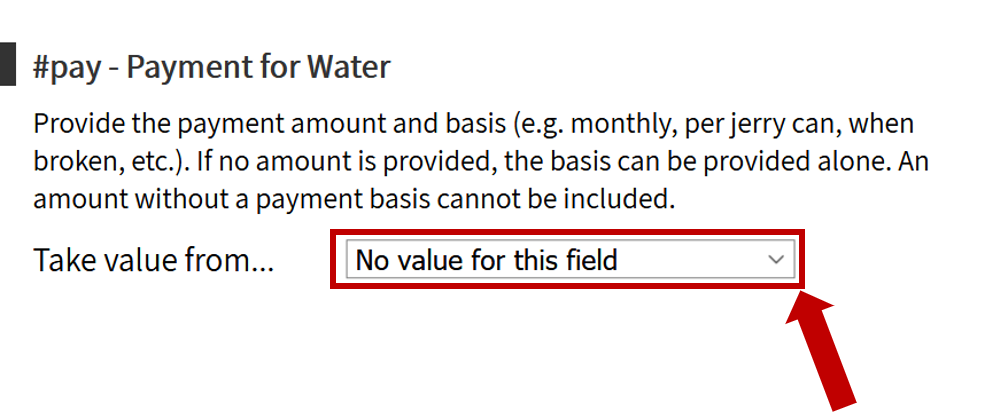
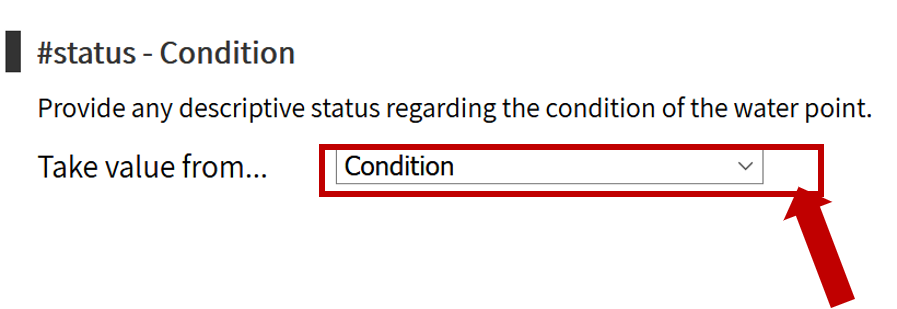
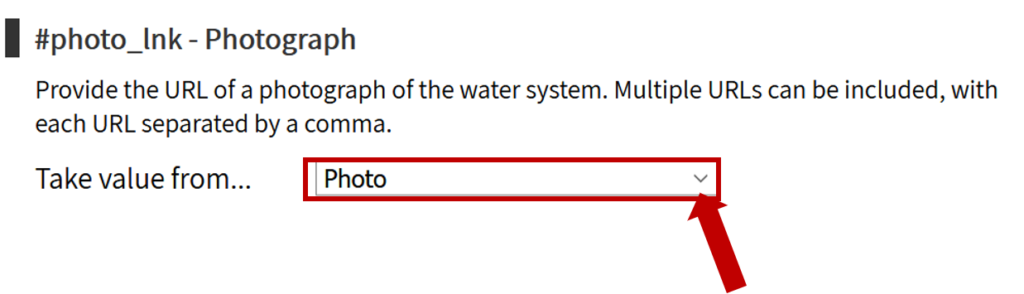
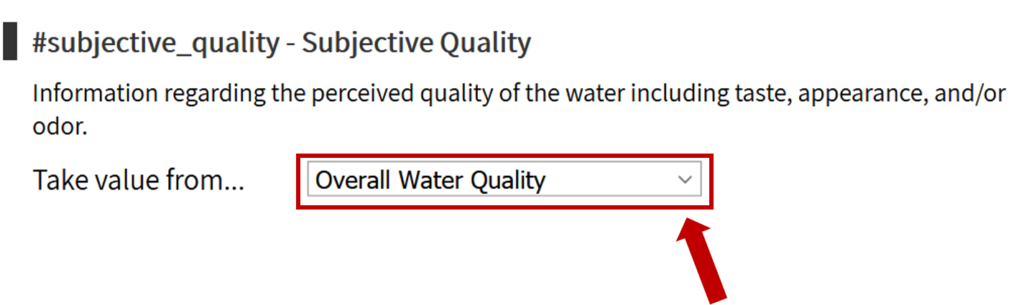
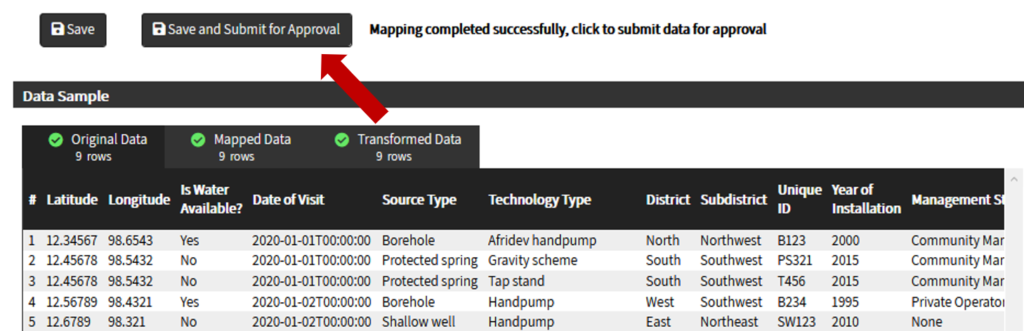
The first step is to review the WPDx data standard and compare with your organization’s dataset. The ingestion notes file can help you document how to map your data to the standard which will save you time later in the process.
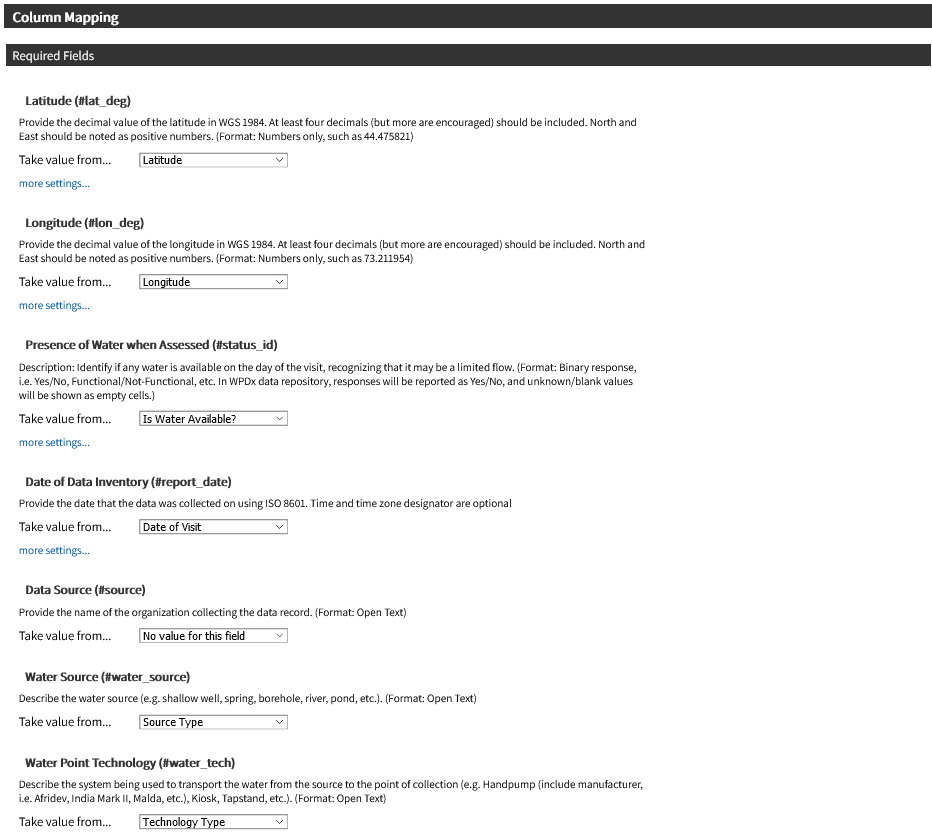
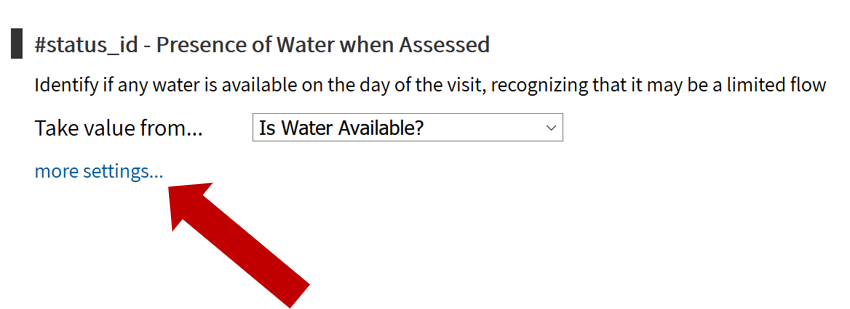
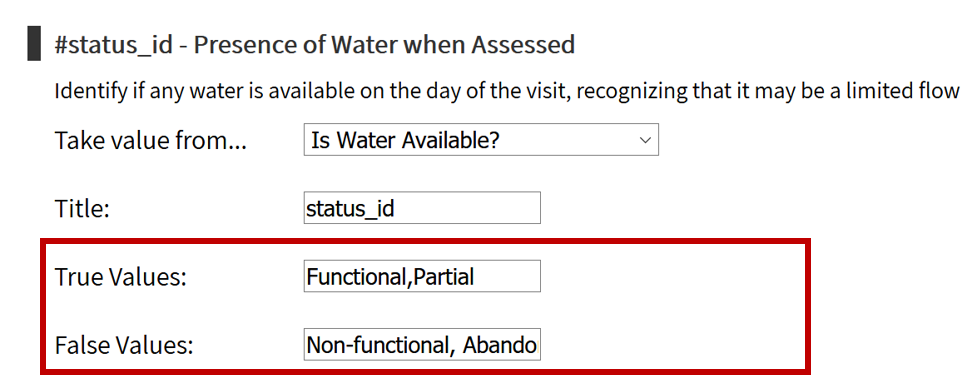
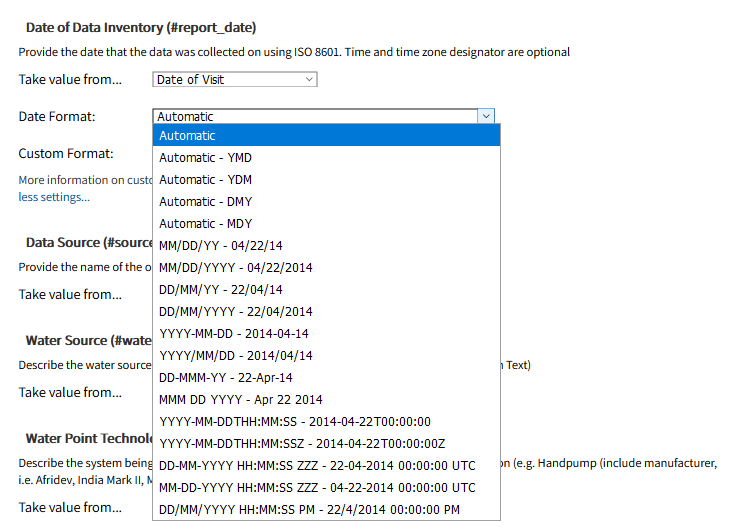
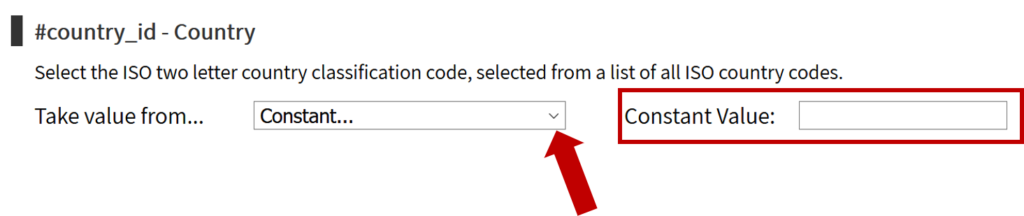
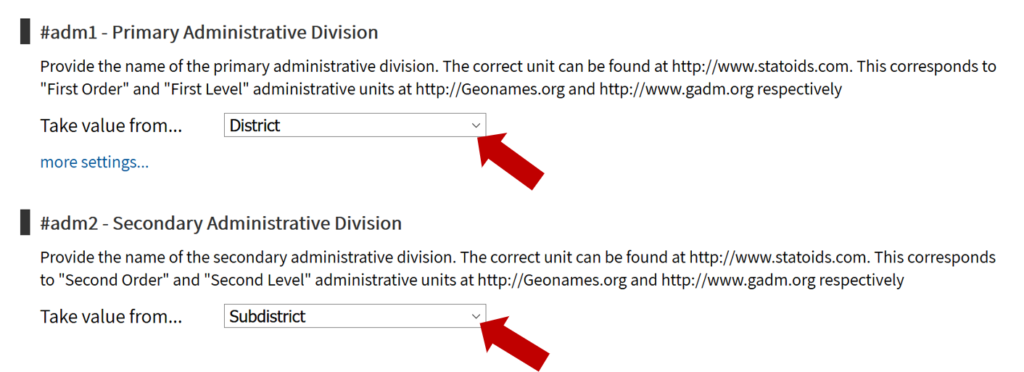
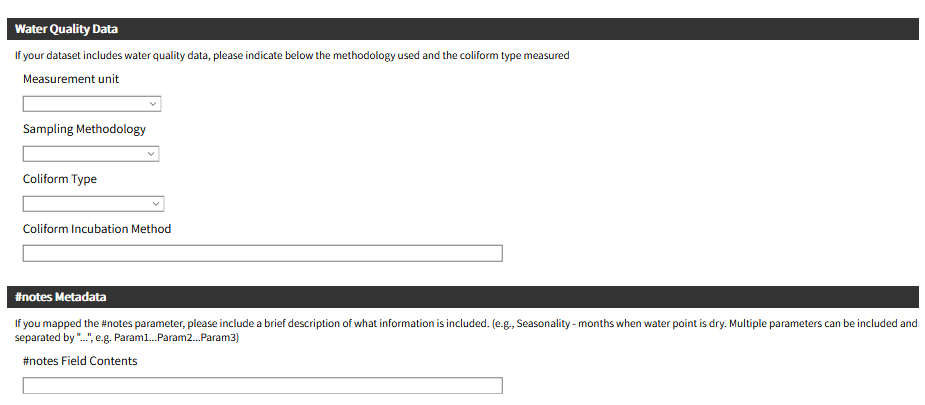
To upload data, the minimum requirements are for the dataset to include location (latitude, longitude in decimal degrees), presence of water when assessed (functional status), date of data inventory, data source (organization providing the data), and information on either/both the source and technology of the water point. While these are the minimum requirements, we highly encourage organizations to share as many parameters as possible to provide a more complete entry. These additional parameters, such as install year or management are utilized in the predict water point status tool.
v\:* {behavior:url(#default#VML);}o\:* {behavior:url(#default#VML);}
w\:* {behavior:url(#default#VML);}
.shape {behavior:url(#default#VML);}
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}